


One of the challenges in responding to cyber threats is monitoring and responding to attacks that continuously evolve in their methods and techniques. Relying solely on signature-based detection, which identifies specific characteristics of attack patterns, may not be sufficient. It’s necessary to also incorporate anomaly detection or abnormal behavior analysis for more comprehensive coverage. Although there are tools available today to assist in detecting such incidents, the ability of analysts to understand how these tools work or to identify abnormalities that the tools might miss can greatly enhance the accuracy of threat response.
The incident response process, as recommended by NIST SP 800-61r2, is divided into four steps. This article focuses on step 2, Detection and Analysis. The aim is to help those involved in threat analysis understand how to detect and analyze malicious behavior. Key points from two documents—Technical Approaches to Uncovering and Remediating Malicious Activity and Federal Government Cybersecurity Incident and Vulnerability Response Playbooks—will be referenced, with the content divided into three sections: Log to collect, Methods for Analyzing Abnormal Behavior, and Recommended Response Actions.
Part 1: Log to collect
When considering which logs to collect, you can start by looking at what is required by law (e.g., the Computer Crime Act of 2021). Then, expand to cover the requirements of audits or regulatory bodies, and define the use cases along with the urgency level of each event.
Another approach is to choose use cases first (e.g., referencing techniques in MITRE ATT&CK that are commonly used by attackers). Afterward, link the log sources to the relevant techniques and specify indicators to create detection rules. The selection of use cases can be based on several factors, such as activities that are inconsistent with the organization’s IT security policy, alerts from security analytics devices, threat intelligence data, or information from other sources useful for monitoring abnormal events.
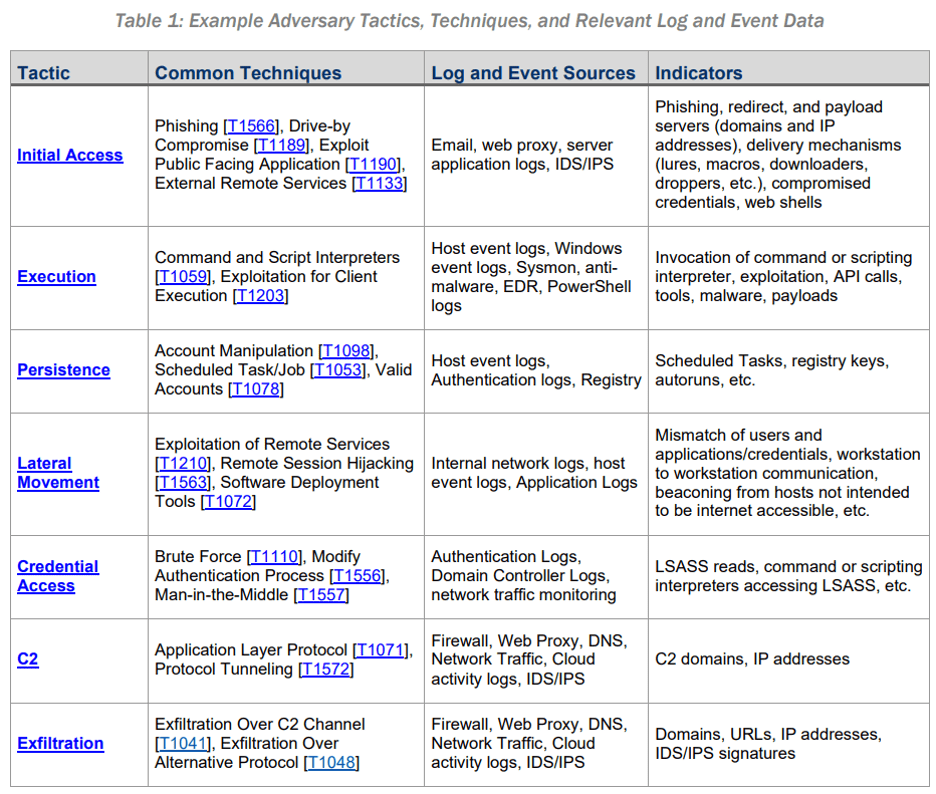
The selection of indicators to create detection rules can be based on attack vectors and potential impacts on the systems to be monitored. For example, consider how attackers can access the system, which accounts have elevated privileges, and if successful, how malware might be installed or a backdoor created for future access. Additionally, assess whether lateral movement to other systems within the organization is possible, or if sensitive data could be directly transferred from the compromised system. This information can help identify related events for crafting detection rule logic.
Part 2: Methods for Analyzing Abnormal Behavior
After selecting log sources and evaluating indicators based on potential threats, the next step is to define conditions for detecting or searching for abnormal events. This can be divided into four approaches:
- Indicator of Compromise (IOC) Search – This involves directly searching for identified malicious data (e.g., domains, IP addresses, file hashes) in logs. The advantage is that it is straightforward with a lower chance of false positives. However, the downside is that IOC-based detection can be easily bypassed, and network-related IOCs may be dynamic, leading to false positives over time.
- Frequency Analysis – This method identifies abnormalities based on human behavior by analyzing datasets to establish patterns of normal activities, then monitoring for events that fall outside these established patterns. For example, logins outside working hours, logins from unfamiliar devices, or the use of previously unused ports.
- Pattern Analysis – This method looks for abnormalities caused by malware or automated scripts, which differ from normal human behavior. For instance, recurring events occurring at the same time every day.
- Anomaly Analysis – Analysts collaborate with system administrators to look for behavior or errors in the system that are abnormal but may not yet be definitively identified as an attack.
Methods for detecting abnormalities on hosts generally focus on analyzing data from processes, applications, files, user accounts, and event logs present on the machines. Some abnormalities are clear indicators of an attack, while others may require confirmation from relevant personnel. Examples of detecting abnormalities on a host include:
- Processes attempting to connect to the internet and send data to suspicious endpoints, which could be botnet behavior sending beacon signals to communicate with command and control systems.
- Detection of PowerShell command lines encoded in Base64, which may indicate an attempt to bypass detection of malicious command execution.
- Suspicious login attempts, such as successful logins from IPs that have never been used before.
- Accounts that cannot be identified or are being used for unclear purposes.
- Programs or scripts being executed from the temp directory, which should not typically be used for installing or running programs.
For network-based detection, the focus is on detecting anomalies in DNS traffic, the use of remote access protocols (e.g., RDP, VPN, SSH), file transfer protocols (e.g., FTP, torrent), or other communication channels outside of authorized use. Examples of detecting abnormalities on the network include:
- Internal machines opening ports that allow external network connections, which were not requested or cannot be identified as specific services.
- Abnormal spikes in traffic, which could indicate data uploads to an external network, or patterns of data transmission (e.g., a connection attempt every hour), which may indicate malware activity.
- Connections to IPs or domains known to be associated with malware or attacks, especially when multiple connection attempts are made even after being blocked. This may suggest malware infection.
Part 3: Recommended Response Actions
The incident response process, following detection and analysis, moves to containment, eradication, and recovery once confirmation has been made that the endpoint has been successfully compromised. The next step is to limit the damage to prevent the affected system from being used to spread to others. Afterward, malware is removed or any changes made by the attacker are reversed, and the system is restored to normal operations. However, one process that may introduce risks (or further damage) is when taking action too early before transitioning from analysis to containment.
The purpose of conducting analysis is to assess the damage, impact, and potentially investigate the attack vector and links to the attack group involved. There are two main points to be cautious about: first, ensuring the preservation of evidence or minimizing interference with volatile data on the compromised system (e.g., avoiding restarting or shutting down the system before evidence collection); and second, preventing the attacker from becoming aware of detection (e.g., avoiding pinging, connecting to IPs, or visiting the attacker’s websites), as the attacker may change tactics or attempt to destroy evidence or further compromise data on the system they control.
The purpose of containment is to limit the scope of damage after a system has been compromised by an attacker. There are several approaches for implementation, such as disconnecting the affected system from the organization’s main network, blocking connections to IPs or domains associated with the attack, or suspending access rights to accounts that the attacker has gained unauthorized access to. However, some actions may require careful consideration to ensure thorough verification, as the attacker may change tactics or utilize other undiscovered channels to re-enter the system. For instance, blocking only the attacker’s IP or domain might prompt them to switch to a new IP or domain and launch another attack. Similarly, suspending access to the compromised account may lead the attacker to use another account that hasn’t been detected yet. Therefore, before containment is executed, it’s important to verify that all necessary actions have been taken, and continued monitoring may be required to detect any abnormal activity even after containment is in place.

Conclusion
Detecting and analyzing threats based on malicious behavior, as well as choosing appropriate approaches to limit the scope of damage, are key factors that can help organizations respond to attacks accurately and comprehensively. Whether it’s collecting log, anomaly detection, or selecting a response strategy to address the issue, these tasks require collaboration and information exchange between system administrators and threat analysis teams. This ensures that sufficient information is available to make timely and informed decisions in response to the situation.
MFEC is a comprehensive IT consulting and solution development company that plays a vital role in establishing IT foundations for leading clients across various industries. With over 20 years of experience, the company leverages its strength in providing Cyber Security services and IT solutions to organizational clients. MFEC offers a Cyber Security Operation Center (CSOC) service, which provides 24/7 monitoring, as well as precise analysis and timely response to security incidents.
For organizational clients and businesses interested in using the CSOC as a service or other Cyber Security-related services, please contact: email : infosec@mfec.co.th

